A short introduction of the dataset
We picked the dataset on spamming by sms. It consisted of 5572 rows of data and with two columns one being the SMS message and the other depicting if the message was spam or ham. 13% of the messages were marked as spam. It consisted of different types of messages, some being very short and others longer with some being very legible, meanwhile others consisted mostly of weird symbols.
The data cleaning process and its result
The first step for cleaning our data was to remove unwanted things from the dataset. This includes duplicates or irrelevant data.
The first thing that we checked was if we have any missing values. Our dataset did not have any missing values so we did not have to replace anything.
We started with 5572 rows of data and after deleting duplicates we ended up having 5169 rows of data.
After that we deleted irrelevant data from our dataset. This included some symbols from the data:
. We also decided to remove a phrase that was used often but would not give us any valuable information: <#>.
Comparing different Machine Learning algorithms with the dataset.
Models we chose to generate:
Naive Bayes
Generalized Linear Model
Fast Large Margin
Deep learning
Decision Tree
Random Forest
Gradient Boosted Trees
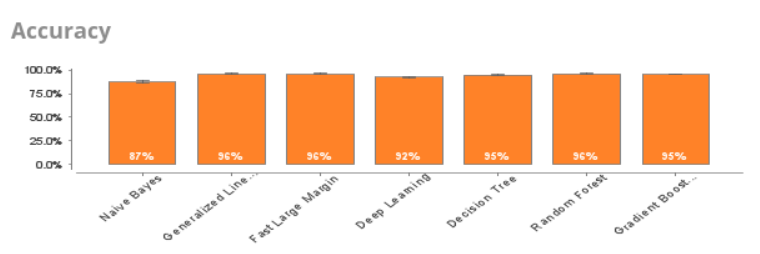
The accuracy of results was very high and we got an overview of the total time it took for the algorithms to train and score the dataset.

Process
We Imported the dataset to Rapidminer and changer column v1 to label because we want to know if an email is considered spam or ham.

Looked over the statistics of imported data to see if there are any missing values. No missing values were detected.

Since we did not need to change any of the data the only thing we did was to rename the columns. v1 changed to Content and v2 changed to Spam or ham.

After that we started the Auto model. Selected task was to predict if an email is spam or ham. Prepared targets showed that 4,516 was marked as ham and 653 was marked as spam in the given dataset.

After that we selected the inputs as v2 so ham or spam.

Process graph

The results that were obtained
We ran the algorithms and got following grading results:
Naive Bayes – spam 9%, ham 91%
Generalized Linear Model – spam 33%, ham 67%
Fast Large Margin – spam 17%, ham 83%
Deep learning – spam 1%, ham 99%
Decision Tree – spam 4%, ham 96%
Random Forest – spam 11%, ham 89%
Gradient Boosted Trees – spam 10% 90%
Naive Bayes
Naive Bayes is an algorithm for predictive modeling. It is a high-bias, low-variance classifier, and it can build a good model even with a small data set. Typical use cases involve text categorization, including spam detection, sentiment analysis, and recommender systems.
In our data set naive bayes predicted that about 91% of given data is categorized as ham and 9% as spam. Important factors for contradicting ham included dude, wat, staying and bluetooth. Important factors for supporting ham included once, min and todays.


Generalized Linear Model
The GLM generalized linear regression by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.
In our data set, the generalized linear model predicted that about 67% of given data is categorized as ham and 33% as spam. Important factors for contradicting ham included service, claim, mobile, txt, ringtone, pobox and landline.
This model gave us the highest percentage of spam.


Fast Large Margin
The Fast Large Margin operator applies a fast margin learner based on the linear support vector learning. Although the result is similar to those delivered by classical SVM or logistic regression implementations, this linear classifier is able to work on a data set with millions of examples and attributes.
In our data set fast lane margin predicted that about 83% of given data is categorized as ham and 17% as spam. Important factors for contradicting ham included http, dating, ringtone, rates and receive. Important factors for supporting ham included yup and words.


Deep learning
Deep Learning is based on a multi-layer feed-forward artificial neural network that is trained with stochastic gradient descent using back-propagation. The network can contain a large number of hidden layers consisting of neurons with tanh, rectifier and maxout activation functions.
In our data set deep learning predicted that about 99% of given data is categorized as ham and 1% as spam. Important factors for contradicting ham included muz, awaiting and http. Important factors for supporting ham included test, numbers, way and look.


Decision Tree
The Decision Tree Operator creates one tree, where all Attributes are available at each node for selecting the optimal one with regards to the chosen criterion. Since only one tree is generated the prediction is more comprehensible for humans, but might lead to overtraining.
In our data set the decision tree predicted that about 96% of given data is categorized as ham and 4% as spam. Important factors for contradicting ham included services, claim, dating, alrite, ringtone and break. Important factors for supporting ham included calls.


Random Forest
The Random Forest Operator creates several random trees on different Example subsets. The resulting model is based on voting of all these trees. Due to this difference, it is less prone to overtraining.
In our data set the random forest predicted that about 89% of given data is categorized as ham and 11% as spam. Important factors for contradicting ham included log, future, cash, customer. Important factors for supporting ham included seem, project and needs.


Gradient Boosted Trees
The Gradient Boosted Trees Operator trains a model by iteratively improving a single tree model. After each iteration step the Examples are reweighted based on their previous prediction. The final model is a weighted sum of all created models. Training parameters are optimized based on the gradient of the function described by the errors made.
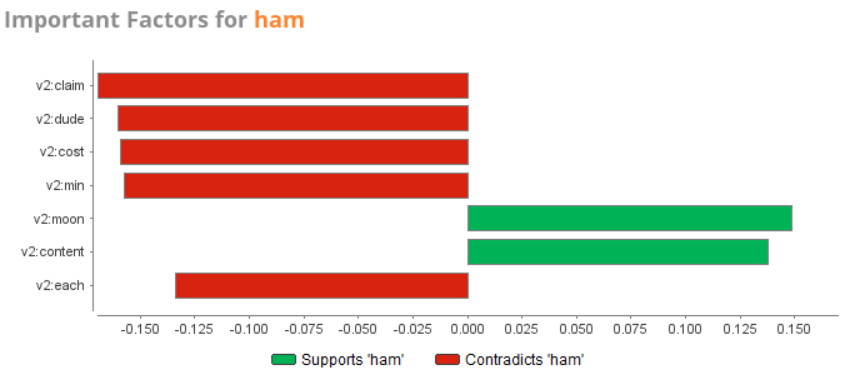
In our data set the gradient boosted tree predicted that about 90% of given data is categorized as ham and 10% as spam. Important factors for contradicting ham included claim, dude, cost, min and each. Important factors for supporting ham included moon and content.

An interpretation of the results and their implications.
From the filtered dataset 12.65% of the messages were labeled as spam. We also made a word cloud to identify the frequently occurring word in both types of messages. The words were color coded by their type. Blue being ham and red being spam.



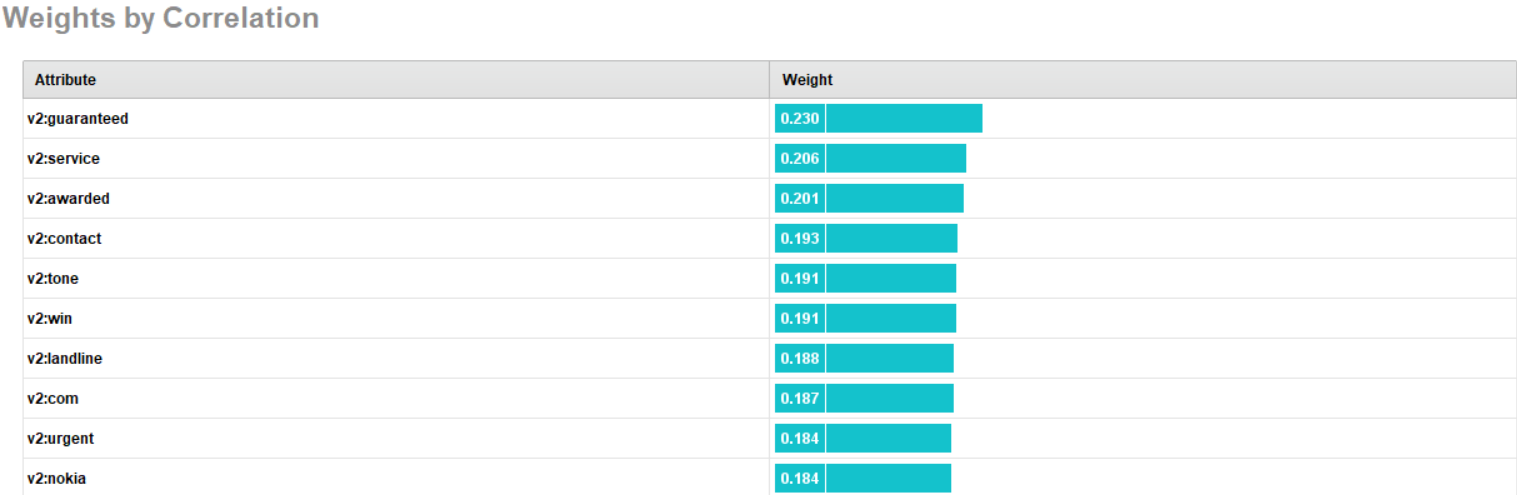
The most common words used by spam messages were usually selected to try and persuade the user. We generated a table of top 10 most recurring words and their weight, which indicated the frequency of use. The top 10 most recurring words ordering by their weight were guaranteed, service, awarded, contact, tone, win, landline, com, urgent and nokia.
A conclusion of the report.
In conclusion we used a new and interesting tool called RapidMiner for data analysis. Our dataset consisted of different SMS messages that were prelabeled. We used RapidMiners automated machine learning functionality with different algorithms to create the models.
After completing the task we thought that in the data cleaning set we could also have corrected all grammatical spelling mistakes. This would have helped us in a way that these words would be counted as one and not as two different words. It would have also been interesting to have even more data to work with since a lot of the SMS messages were very short and had no particular context.
Overall it was interesting to see how easy the process was in reality and how the words in messages had either a positive or negative undertone to them. We will probably take that into account when sending messages in the future.
Testing dataset
After having a meeting with our lecturers we decided to make a testing dataset that included 500 rows of ham and 500 rows of spam.


We chose to generate the same models as before:
Naive Bayes
Generalized Linear Model
Fast Large Margin
Deep learning
Decision Tree
Random Forest
Gradient Boosted Trees
The accuracy of results was a lot smaller than before. This might be because the testing dataset we made was also significantly smaller than our actual dataset.


We ran the algorithms and got following grading results:
Naive Bayes – spam 7% , ham 93%
Generalized Linear Model – spam 56%, ham 44%
Fast Large Margin – spam 51%, ham 49%
Deep learning – spam 26%, ham 74%
Decision Tree – spam 30%, ham 70%
Random Forest – spam 43%, ham 57%
Gradient Boosted Trees – spam 48%, ham 52%
It was very interesting to see that the results from different algorithms varied a lot. The cause of this might be that a lot of spam SMS messages contained normal words that made it seem more like ham than spam. This shows us that from a short SMS message and much smaller dataset the obtained results might not be as trustable. A lot of the words from the messages were found in both ham and spam.

https://ifi7167socialcomputing.wordpress.com/2020/10/29/data-analysis-project-2-pick-up-a-dataset/